Ans: SAP HANA is an in-memory database.
- It is a combination of hardware and software made to process massive real time data using In-Memory computing.
- It combines row-based, column-based database technology.
- Data now resides in main-memory (RAM) and no longer on a hard disk.
- It’s best suited for performing real-time analytics, and developing and deploying real-time applications.
SAP HANA is equipped with multiengine query processing environment which supports relational as well as graphical and text data within same system. It provides features that support significant processing speed, handle huge data sizes and text mining capabilities.
To know more, check the article SAP HANA Introduction for Beginners
2. So is SAP making/selling the software or the hardware?
Ans: SAP has partnered with leading hardware vendors (HP, Fujitsu, IBM, Dell etc) to sell SAP certified hardware for HANA.
SAP is selling licenses and related services for the SAP HANA product which includes the SAP HANA database, SAP HANA Studio and other software to load data in the database.
To know more, check the article SAP HANA Hardware
3. What is the language SAP HANA is developed in?
Ans: The SAP HANA database is developed in C++.
4. What is the operating system supported by HANA?
Ans: Currently SUSE Linux Enterprise Server x86-64 (SLES) 11 SP1 is the Operating System supported by SAP HANA.
5. Can I just increase the memory of my traditional Oracle database to 2TB and get similar performance?
Ans: NO.
You might have performance gains due to more memory available for your current Oracle/Microsoft/Teradata database but HANA is not just a database with bigger RAM.
It is a combination of a lot of hardware and software technologies. The way data is stored and processed by the In-Memory Computing Engine (IMCE) is the true differentiator. Having that data available in RAM is just the icing on the cake.
6. What are the row-based and column based approach?
Row based tables:
- It is the traditional Relational Database approach
- It store a table in a sequence of rows
Column based tables:
- It store a table in a sequence of columns i.e. the entries of a column is stored in contiguous memory locations.
- SAP HANA is particularly optimized for column-order storage.
SAP HANA supports both row-based and column-based approach.
Following figure explains the difference between the two storage mechanism.

To know more, check the article Column Data Storage Vs Row Data Storage in HANA
7. What are the advantages and disadvantages of row-based tables?
Ans: Row based tables have advantages in the following circumstances:
- The application needs to only process a single record at one time (many selects and/or updates of single records).
- The application typically needs to access a complete record (or row).
- Neither aggregations nor fast searching are required.
- The table has a small number of rows (e. g. configuration tables, system tables).
Row based tables have dis-advantages in the following circumstances:
- In case of analytic applications where aggregation are used and fast search and processing is required. In row based tables all data in a row has to be read even though the requirement may be to access data from a few columns.
8. What are the advantages of column-based tables?
Ans: Advantages:
- Faster Data Access:
Only affected columns have to be read during the selection process of a query. Any of the columns can serve as an index.
- Better Compression:
Columnar data storage allows highly efficient compression because the majority of the columns contain only few distinct values (compared to number of rows).
- Better parallel Processing
In a column store, data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core
9. In HANA which type of tables should be preferred - Row-based or Column-based?
Ans: SQL queries involving aggregation functions take a lot of time on huge amounts of data because every single row is touched to collect the data for the query response.
In columnar tables, this information is stored physically next to each other, significantly increasing the speed of certain data queries. Data is also compressed, enabling shorter loading times.
Conclusion:
To enable fast on-the-fly aggregations, ad-hoc reporting, and to benefit from compression mechanisms it is recommended that transaction data is stored in a column-based table.
The SAP HANA data-base allows joining row-based tables with column-based tables. However, it is more efficient to join tables that are located in the same row or column store. For example, master data that is frequently joined with transaction data should also be stored in column-based tables.
Few more important points about column table:
- HANA modeling views are only possible for column tables. Row based tables cannot be used in modeling views.
- For that reason Replication Server creates SAP HANA tables in column store by default.
- Data Services also creates target tables in column store as default for SAP HANA database
- The SQL command to create column table: “CREATE COLUMN TABLE Table_Name..”.
- The data storage type of a table can be modified from Row to Column storage with the SQL command “ALTER TABLE Table_Name COLUMN“.
10. Why materialized aggregates are not required in HANA?
Ans: Since the SAP HANA database resides entirely in-memory all the time, additional complex calculations, functions and data-intensive operations can happen on the data directly in the database. Hence materialized aggregations are not required.
It also provides benefits like
- Simplified data model
- Simplified application logic
- Higher level of concurrency
11. How does SAP HANA support Massively Parallel Processing?
Ans: With availability of Multi-Core CPUs, higher CPU execution speeds can be achieved.
Also HANA Column-based storage makes it easy to execute operations in parallel using multiple processor cores.
In a column store data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core.
In addition operations on one column can be parallelized by partitioning the column into multiple sections that can be processed by different processor cores. With the SAP HANA database, queries can be executed rapidly and in parallel.
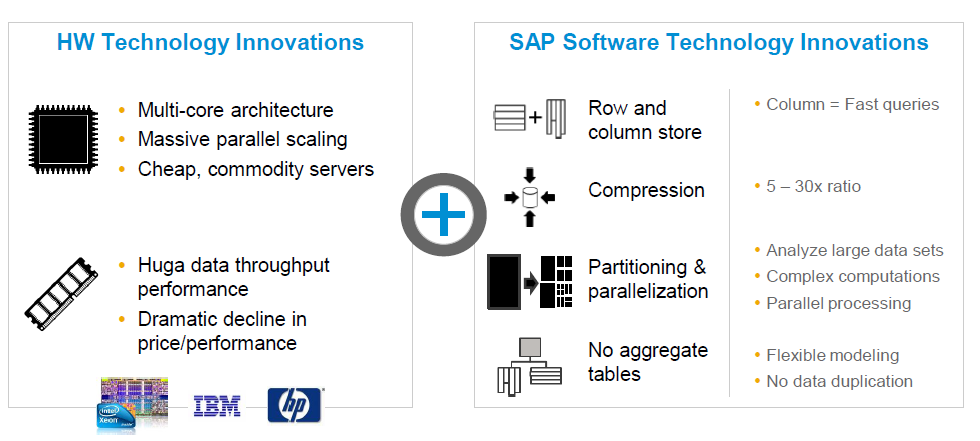
12. Why SAP HANA is fast?
Ans:

13. Describe SAP HANA Database Architecture in brief.
Ans:

The SAP HANA database is developed in C++ and runs on SUSE Linux Enterpise Server. SAP HANA database consists of multiple servers and the most important component is the Index Server. SAP HANA database consists of Index Server, Name Server, Statistics Server, Preprocessor Server and XS Engine.
Index Server:
- Index server is the main SAP HANA database component
- It contains the actual data stores and the engines for processing the data.
- The index server processes incoming SQL or MDX statements in the context of authenticated sessions and transactions.
Persistence Layer:
The database persistence layer is responsible for durability and atomicity of transactions. It ensures that the database can be restored to the most recent committed state after a restart and that transactions are either completely executed or completely undone.
Preprocessor Server:
The index server uses the preprocessor server for analyzing text data and extracting the information on which the text search capabilities are based.
Name Server:
The name server owns the information about the topology of SAP HANA system. In a distributed system, the name server knows where the components are running and which data is located on which server.
Statistic Server:
The statistics server collects information about status, performance and resource consumption from the other servers in the system.. The statistics server also provides a history of measurement data for further analysis.
Session and Transaction Manager:
The Transaction manager coordinates database transactions, and keeps track of running and closed transactions. When a transaction is committed or rolled back, the transaction manager informs the involved storage engines about this event so they can execute necessary actions.
XS Engine:
XS Engine is an optional component. Using XS Engine clients can connect to SAP HANA database to fetch data via HTTP.
14.What is ad hoc analysis?
Ans: In traditional data warehouses, such as SAP BW, a lot of pre-aggregation is done for quick results. That is the administrator (IT department) decides which information might be needed for analysis and prepares the result for the end users. This results in fast performance but the end user does not have flexibility.
The performance reduces dramatically if the user wants to do analysis on some data that is not already pre-aggregated. With SAP HANA and its speedy engine, no pre-aggregation is required. The user can perform any kind of operations in their reports and does not have to wait hours to get the data ready for analysis.
15. What are the types of modeling views in HANA?
Ans: There are 3 types of modeling in HANA:
- Attribute View
- Analytic View
- Calculation View
16. What is a Delivery Unit?
Ans: A delivery unit could be regarded as a collection of several packages, used for transporting content from one HANA system to another.
Delivery unit (DU) is a container used by the Life Cycle Manager (LCM) to transport repository objects.
17. There are 2 types of packages in content. What are they?
Ans: In HANA, 2 types of packages can be created.
18. What are the different engines available in HANA?
Ans: In HANA there are mainly 3 types of engines.
19. There is an analytic view which has calculated column defined. Which engine will be used when calling this view?
Ans: By default analytic view is executed in OLAP engine. But this changes when analytic view has a calculated column.
If an analytic view has a calculated column then internally it is treated as calculation view and executed in calculation engine.
20. If my Analytic View foundation is joined to attribute views, is both the OLAP and JOIN Engine used?
Ans: Nope - during activation of the analytic views, the joins in the attribute views get 'flattened' and included in the analytic view run time object. Only the OLAP engine will be used then.
Ans: A delivery unit could be regarded as a collection of several packages, used for transporting content from one HANA system to another.
Delivery unit (DU) is a container used by the Life Cycle Manager (LCM) to transport repository objects.
17. There are 2 types of packages in content. What are they?
Ans: In HANA, 2 types of packages can be created.
- Structural: Package only contains sub-packages. It cannot contain repository objects.
- Non-Structural: Package contains both repository objects and sub-packages.
18. What are the different engines available in HANA?
Ans: In HANA there are mainly 3 types of engines.
- Join Engine: used for attribute views
- OLAP engine: used for analytic views
- Calculation Engine: used for calculation views
19. There is an analytic view which has calculated column defined. Which engine will be used when calling this view?
Ans: By default analytic view is executed in OLAP engine. But this changes when analytic view has a calculated column.
If an analytic view has a calculated column then internally it is treated as calculation view and executed in calculation engine.
20. If my Analytic View foundation is joined to attribute views, is both the OLAP and JOIN Engine used?
Ans: Nope - during activation of the analytic views, the joins in the attribute views get 'flattened' and included in the analytic view run time object. Only the OLAP engine will be used then.
No comments:
Post a Comment