In this “how-to” post I am aiming to cover additional parts that arise while using HANA Live models in a sidecar scenario to your main (mature) SAP installation on a different DB. This blog post is of lesser interest for those cases, where an existing ECC / CRM system is migrated to HANA DB due to the fact that required tables are readily available under SAP_ECC / SAP_CRM schema. All you need to do is – install the HANA Live content and start using / modifying it.
Just a short recap, the scenario I am trying to cover here is the least-risk (and, possibly, cost) approach to leverage advantages of HANA with minor changes to existing ECC/CRM landscape, when an additional HANA instance is connected to the “main” system, running on traditional relational database. It may be an own HANA box, or any of the cloud solutions on the market.
")
")
")
")
")
Just a short recap, the scenario I am trying to cover here is the least-risk (and, possibly, cost) approach to leverage advantages of HANA with minor changes to existing ECC/CRM landscape, when an additional HANA instance is connected to the “main” system, running on traditional relational database. It may be an own HANA box, or any of the cloud solutions on the market.
")
Just worth to mention, that HANA Live is a set of HANA Virtual Data Models (read HANA-views), that cover Reporting / Analytics needs directly on HANA system without the need to batch-load the data out of the HANA DB. To my personal opinion, HANA Live is a great delivery by SAP, which already contains quite some pre-built models (at the moment of writings this blog about a 1000 of them for ECC and same for CRM). So, like with Business Content for BW, you are not starting from scratch, but already have something to impress your stakeholders with
Unlike Business Content, it is an all-or-nothing installation and new versions overwrite any modifications you have made without asking you upfront, therefore it is always advised to follow Copy --> Modify approach.
Cold HANA Live install & Pre-analysis
The goal of this step is to understand, which tables you really need (remember, we will need to setup their replication from a current DB of ECC/CRM system to the HANA box), which data out of those tables we need, both field and content-wise.
- Check if Schema mapping is good. Do not start installing before it is.
- Download and Install your main HANA Live component(s) for ECC / CRM. Do not forget to install Explorer, too (HCO_HBA_AF_EXPLORER), it will make life much easier. Your models will not get successfully activated due to missing tables at this point, but bear with me.
- Find out all the tables you will need (via Explorer). Its default URL is- http://<HANA Server Host>:80<SAP HANA Instance Number>/sap/hba/explorer. Note, that you can select multiple entries in Explorer and export a CSV list of required tables altogether. I followed this approach:
- All generally required SAP tables (Note 1782065)
- All Master Data --> Save the CSV
- All SD --> Save the CSV
- All FICO --> Save the CSV,
- Etc., etc.
I ended up with a combined list of like 230 tables. If you think full-blown approach is better, you may use a list of all 550 tables required for ECC, use Note 1781992 to obtain it. Similar note exists for CRM, too.
- Analyze table sizes (if your SAP runs on Oracle, table DBSTATTORA might give you an idea )and think of any filtering you may want to do. Especially useful might be filtering on the year/date/document ranges if you have long history. Without this, your SLT development system may start crying. Put that into your notes.
- Analyze, which fields you can avoid loading. John Appleby says in his blog that “wide” table perform worse on loading. Especially both “big” and “wide”. To get an idea, how wide your tables are, check SAP table DD03L. You probably will want to cross-check how much of that is used in HANA Live models, especially big ones. I just parsed the XMLs of some most-relevant models to get the list of table fields used. In my case we needed about 20-30% of fields anyway… Once done, put that into your notes.
SLT setting - general part
The system that will “shadow” the selected ECC / CRM tables is SLT (aka SAP Landscape Transformation, aka Replication Server). It is often installed on the same box for DEV and QAS environments, but a dedicated SLT system for PROD use.
"Table space assignment" --> Own table space is recommended for easier monitoring of the table sizes of the logging tables (Section 5.6) of the Installation Guide.
Do not underestimate the:
Number of background jobs needed on SLT Server (consult the SLT Operations Guide section 3.5.1)
Number of Load and Replication jobs you configure on SLT itself (consult the same section further)
These are the key things not to miss out, but we trust BASIS have done their job right
SLT Setting – table-wise
You may want to start with a small table to find out if your ideas work and then do with bigger. For monitoring, user Transaction LTRC.
Most of the “Advanced replication settings”, addressed below, are found in Transaction LTRS.
Note, that loading using SLT happens like this:
- First it drops the table(s) specified
- It recreates the tables and starts loading sequentially (sorted by table name irrespective of how you put it into the CSV file).
Tables: Field-wise
If you want to restrict the fields for transfer (e.g. for those huge tables where only 20 fields are used in HANA models out of 250 available in SAP), right-click on “Table Settings” and start from here.
")
* A tip: you can cross-check the “Original” structure of a particular table in a metadata table DD03L versus the “Desired” structure needed for HANA Live model perspective (e.g. parsing an XML of a model that uses a given table). A simple VLOOKUP in XLS will get you to the fields you want to exclude and you can do that en-masse.
Then you can click on “Mass change” and add them all.
")
Tables: Filtering
“Official” (works on any version of SLT)
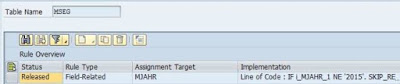
If you need to restrict the data (filter), use transaction code LTRC, right-click “Rule Assignment”, “Add a Table” and create a field or event based rule.

")
More on those, consult section 5 of the guide found attached to a Note 1733714 - Guide for Advanced Replication Settings. If you have followed training HA300, it is all there, too
While loading, you should notice, that it will first read all the data records from SAP to SLT, then do the filtering in SLT and transfer. For a better solution, you should check the next chapter.
The “other one” (works on SP06 and up)
If you want to avoid the extensive data volume transfer between the systems (trust me, you probably do want), read this blog post by Tobias Koebler, where it is explained, how to use a table DMC_ACSPL_SELECT so filtering is executed in the source.
To illustrate the difference – here we go: both source tables on the picture below are 24 mil records each, their processing time has a difference 1:10 times. Note, that I used an SLT filter on MSEG (87% of time on read because it reads everything) and SQL filter on BKPF (17% of time on reading).
Try imagine the difference on a 1 bill records table
Source: scn.sap.com
No comments:
Post a Comment