1. What happens when you activate an object in HANA?
Ans: When we activate an object, it becomes available for reporting and analysis.
After successful activation of a view, a run time object is created in _SYS_BIC schema.
For example, suppose there is a calculation view CV_VIEW1 in package “MyPackage”. After activating this view, a run time object (column view) will be created in _SYS_BIC schema with name “MyPackage/CV_VIEW1”. This column view is used when we do the data preview of calculation view.
2. What is the difference between Activate and Redeploy?
Ans: Activate - Deploys the inactive objects.
Redeploy - Deploys the active objects in one of the following scenarios:
- If your runtime object gets corrupted or deleted, and you want to create it again.
- In case of runtime problems during object activation, and the object status is still active.
3. How do we control row-level access in HANA?
Ans: Analytic privilege can be used to maintain row-level access. It is used to grant different users access to different portions of data in the same view depending on their business role.
4. What is the importance of _SYS_BI_CP_ALL analytic privilege?
Ans: _SYS_BI_CP_ALL analytical privilege gives access to read from all information model views. We can control this by creating our own analytical privileges and assigning it to only the views that a user should be reporting against and at the level they want to view data.
If a user has the _SYS_BI_CP_ALL Analytic Privilege assigned all other restrictions are ignored. This is generally used for developer roles.
5. Suppose we want to give minimum authorization to end users so that they can only see the output of modeling views. The users should not be able to perform any other activities. What are the privileges that should be assigned to user?
Ans: We need to assign following privileges:
- Read access to the package containing modeling view
- Execute & Select access on _SYS_BI
- Execute & Select access on _SYS_BIC
- Execute on REPOSITORY_REST
6. What are the types of schema in HANA?
Ans: In HANA, there are 3 types of schemas.
- User Defined Schema: These are created by user (DBA or System Administrator)
- SLT Derived Schema: When SLT is configured, it creates schema in HANA system. All the tables replicated into HANA system are contained in this schema
- System Defined Schema: These schemas are delivered with the SAP HANA database and contain HANA system information. There are system schemas like _SYS_BIC, _SYS_BI, _SYS_REPO, _SYS_STATISTICS etc.
7. If tables of a schema are used to build modeling views then it’s necessary to grant SELECT privilege to user _SYS_REPO. Why?
Ans: If tables of a schema (say SCHEMA_ABC) are used to build modeling views, then following SQL statement must be executed before activating any such modeling views.
GRANT SELECT ON SCHEMA SCHEMA_ABC TO _SYS_REPO WITH GRANT OPTION
Think of _SYS_REPO as "the activation guy". It takes your models and creates the necessary runtime objects from them. Therefore user _SYS_REPO needs the allowance to select YOUR tables/views. (If _SYS_REPO user cannot select on the tables specified in the from-clause of the view-definition, it cannot define that view)
If other users need to select this view (obviously this is always the case, otherwise the views would not make sense), then _SYS_REPO needs to have the additional allowance to grant the select further (WITH GRANT OPTION).
Therefor after having activated all your models that access data in your schemas, _SYS_REPO wants to give you (and probably other users) read access to the activated models.
8. What is Auto Documentation feature in HANA?
Ans: When the user creates Views in HANA Studio under “Contents”, he can automatically generate the documentation about the views. This generated document will have the details about all the view belongs to a package which he selected for Auto Documentation.
The user can invoke the Auto Documentation from three places.
- Right click Context menu of the Package or the Views
- On the top right corner of the opened view
- Quick Launch->Content->Auto Documentation
9. What is the difference among Raw Data, Distinct values and Analysis while doing the Data Preview?
Ans:
Raw Data: It displays all attributes along with data in tabular format.
Distinct Values: It displays all attributes along with data in graphical format.
Analysis: It displays all attributes and measures in graphical format.
10. What is Hierarchy? What are the types of hierarchy supported in HANA?
Ans: Hierarchies are used to structure and define the relationships among attributes in a modeling view.
Organizations define hierarchies for information classification, allowing roll-up and drill-down analysis. For example, a sales organization might allocate a sales person to a country and a country to a region. Sales data can then be aggregated and analyzed by region, country, or sales person.
There are two types of hierarchies:
Level Hierarchies are hierarchies that are rigid in nature, where the root and the child nodes can be accessed only in the defined order. For example, organizational structures, and so on.
Parent/Child Hierarchies are value hierarchies, that is, hierarchies derived from the value of a node. For example, a Bill of Materials (BOM) contains Assembly and Part hierarchies, and an Employee Master record contains Employee and Manager data. The hierarchy can be explored based on a selected parent; there are also cases where the child can be a parent.
11. What are the different types of replication techniques?
Ans: There are 3 types of replication techniques:
1. SAP Landscape Transformation (SLT)
2. SAP Business Objects Data Services (BODS)
3. SAP HANA Direct Extractor Connection (DXC)
Note: There is one more replication technique called Sybase replication. It was part of initial offering for HANA replication, but not positioned / supported anymore due to licensing issues and complexity and mostly because SLT provides the same features.
12. What is SLT?
Ans: The SAP Landscape Transformation (LT) Replication Server is the SAP technology that allows us to load and replicate data in real-time from SAP source systems and non-SAP source systems to an SAP HANA environment.
The SAP LT Replication Server uses a trigger-based replication approach to pass data from the source system to the target system.


Ans: There are 3 types of replication techniques:
1. SAP Landscape Transformation (SLT)
2. SAP Business Objects Data Services (BODS)
3. SAP HANA Direct Extractor Connection (DXC)
Note: There is one more replication technique called Sybase replication. It was part of initial offering for HANA replication, but not positioned / supported anymore due to licensing issues and complexity and mostly because SLT provides the same features.
12. What is SLT?
Ans: The SAP Landscape Transformation (LT) Replication Server is the SAP technology that allows us to load and replicate data in real-time from SAP source systems and non-SAP source systems to an SAP HANA environment.
The SAP LT Replication Server uses a trigger-based replication approach to pass data from the source system to the target system.
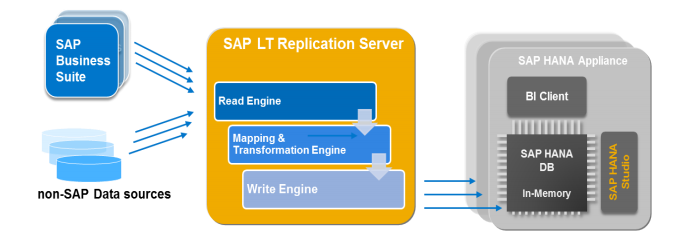
13. What is the advantage of SLT replication?
Ans: Advantages:
- SAP LT uses trigger based approach. Trigger-based approach has no measureable performance impact in source system.
- It provides transformation and filtering capability.
- It allows real-time (and scheduled) data replication, replicating only relevant data into HANA from SAP and non-SAP source systems.
- It is fully integrated with HANA Studio.
- Replication from multiple source systems to one HANA system is allowed, also from one source system to multiple HANA systems.
14. Is it possible to use a replication for multiple sources and target SAP HANA systems?
Ans: Yes, the SAP LT Replication Server supports both 1:N replication and and N:1 replication.
- Multiple source system can be connected to one SAP HANA system.
- One source system can be connected to multiple SAP HANA systems. Limited to 1:4 only.
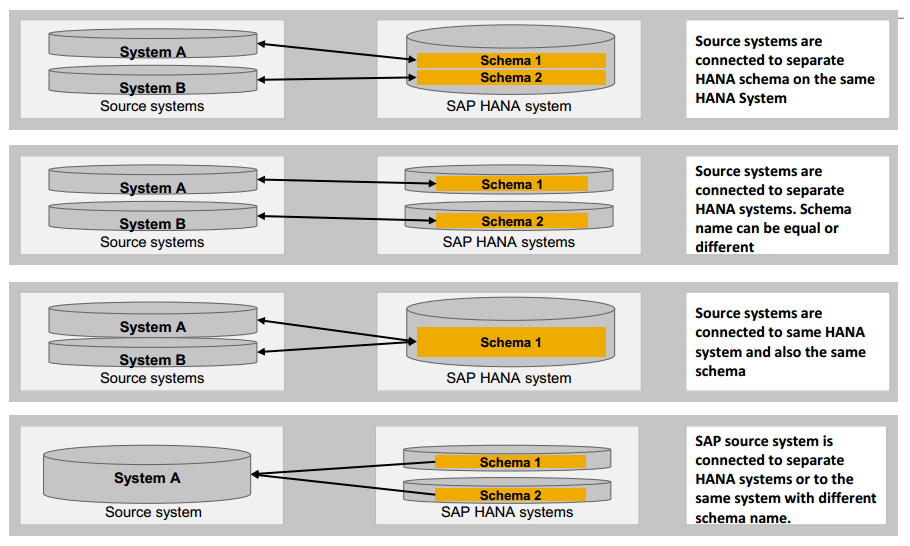
15. Is there any pre-requisite before creating the configuration and replication?
For SAP source systems:
Ans:
- DMIS add-on must be installed in SLT replication server.
- An RFC connection between the SAP source system and the SAP LT Replication Server has to be established.
- User for RFC connection must have the role IUUC_REPL_REMOTE assigned.
- Do not use a DDIC user for RFC connection.
For non-SAP source systems:
- DMIS add-on is not required.
- A database user has to be created with appropriate authorizations in advance and establish the database connection by using transaction DBCO in the SAP LT Replication Server.
- Ensure the database-specific library components for the SAP 7.20 REL or EXT kernel are installed in the SAP LT Replication Server.
16. What is Configuration and Monitoring Dashboard?
Ans: It is an application that runs on SLT replication server to specify configuration information (such as source system, target system, and relevant connections) so that data can be replicated.
It can also use it to monitor the replication status (transaction LTR).
Status Yellow: It may occur due to triggers which are not yet created successfully.
Status Red: It may occur if master job is aborted (manually in transaction SM37).
17. What is advanced replication settings (transaction IUUC_REPL_CONT)?
Ans: The Advanced Settings (transaction IUUC_REPL_CONT) allows you to define and change various table settings for a configuration such as:
- Partitioning and structure changes for target tables in HANA
- Table-specific transformation and filter rules
- Adjusting the number of jobs (and reading type) to accelerate the load/replication process
18. What is Latency?
Ans: It is the length of time to replicate data (a table entry) from the source system to the target system.
19. What is logging table?
Ans: A table in the source system that records any changes to a table that is being replicated. This ensures that SLT replication server can replicate these changes to the target system.
20. What are Transformation rules?
Ans: A rule specified in the Advanced Replication settings transaction for source tables such that data is transformed during the replication process. Example you can specify rule to
- Convert fields
- Fill empty fields
- Skip records
Thanks for sharing the post in brief. Do share more of this post of it's continuation.
ReplyDeleteSpoken English Classes in Chennai
Best Spoken English Classes in Chennai
English Speaking Classes in Mumbai
English Speaking Course in Mumbai
IELTS Coaching in Chennai
IELTS Coaching Centre in Chennai
IELTS Training in Chennai
IELTS Classes in Mumbai
IELTS Coaching in Mumbai
Great info. The content you wrote is very interesting to read. This will loved by all age groups.
ReplyDeleteAngularjs Training in Chennai
Angularjs Course in Chennai
Ethical Hacking Course in Chennai
Tally Course in Chennai
Angular4 Training in Chennai
ux design course in chennai
Angularjs Training Center in Chennai
Angularjs Training Chennai
ccna Training in Chennai
web designing training in chennai